
 艳照门之风云再起
艳照门之风云再起
作家|王兆洋
一个东说念主,待在家里,“散逸”的有一搭没一搭,教师一个要挑战照旧“一统宇宙”的Transformer 的模子。这听起来弥散夸张。
还有更夸张的。
这个模子的雏形比ChatGPT引爆宇宙更早出现,然后不停迭代,OpenAI也凝视到了它,向作家发出邀请,被坐窝绝交,意义是OpenAI不open。而当全宇宙最贤人的头脑王人纷繁涌入这个竞技场和名利场后,这个基本莫得露过面的作家声称:
“当今的AI太浅近了,傻瓜王人不错作念出来。”
况且,他还说,只须他才知说念已矣AGI的谜底。
这个模子便是RWKV,这个东说念主便是彭博。

彭博的知乎个东说念主页面
和今天在大模子鸿沟最常见到的名校诡计机专科毕业,论文等身,师出名门,光鲜亮丽配景的天之宠儿们不同。彭博是个16岁考上港大物理专科,然后在对冲基金作念量化走动,自后又我方创业,制造和售卖一些台灯和音箱产物的“怪东说念主”。以至于,在一些外交媒体上有东说念主告成称号他为“民科”。
关联词与这些争议同期发生的事情是,RWKV这个模子被东说念主提到的频率在加多,他是少有的从架构上作念改进的中国征战者,RWKV的开源生态在壮大,社区自愿为它写了论文,在“无法舞弊的模子评测” Uncheatable Eval 排名榜中,最新的RWKV-6-World 14B 的玄虚评测分数比 llama2 13B 更强。它是首个被Huggingface引入transformer 库的RNN模子。

更有意旨真义的是,这个模子背后的好多想想,彭博作为假想者在饱读励的好多主张,也在被更多东说念主呼应。比如transformer 那篇论文的几个作家在最近初始警告东说念主们宇宙需要更好的模子架构,比如前OpenAI有名研究员Andrej Karpathy也在指示东说念主们RNN的要道依然充满后劲。
我在最近见到了这名深居浅出的玄妙东说念主物,和他聊了聊RWKV的故事。
在对话中,我问他,你合计我方是堂吉诃德如故牛顿。
他回答我:
王人是。
以下为对话实录。
1
RWKV,在Transformer的时间报恩RNN
硅星东说念主:作为RWKV的独一作家,咱们先聊聊RWKV这个架构吧。从降生到最近的RWKV-6,每个版块王人发生了哪些迭代,这些架构上的修改是如何猜度的?
彭博:咱们咫尺最新正在优化的版块是RWKV-7。
在RWKV之前,2020年时,我看了看GPT,立即发现存两个明显的更始办法:
一是引入显式decay。后续在2021年有一个ALiBi提议了访佛的要道。
二是Token-shift。或者说,短卷积。其时我叫time-mixing,自后EleutherAI的lucidrains说不错叫token-shift。我假想Token-shift是为了改善in-context learning。后续在2022年有其它东说念主指出这个,他们称之为induction head。
那么,2020年,我在github发布了一个minGPT-tuned走漏了这些更始的权贵终端,然后在EleutherAI的discord宣传了一下,各人一初始满腹疑心,因为许多东说念主声称的更始施行是无效的,但各人测试后发现照实灵验,于是各人就平稳了。
时于本日,这两个更始是大大宗“非transformer模子”必备的手段。举例SSM团队在2021年的S4时没加token-shift,到2022年的H3就加了短卷积,后续的Mamba天然也加了。
RWKV-1是我将这两种手段加入Apple的Attention Free Transformer,使得AFT已矣了权贵的性能晋升。RWKV-2是我在看到ALiBi用了和我访佛的显式decay后,骤然猜度,如果使用exponential decay,就不错将RWKV写成RNN。这是令东说念主风光的时刻之一。然后我测试发现,性能照实挺好。
RWKV-3使用更全面的token-shift,终端权贵。RWKV-4是贬责RWKV-3的数值稳固性问题,亦然我想的一个贬责要道。最近的xLSTM使用了与我访佛的贬责要道。RWKV-4是我很舒畅的架构,因为它的state相当小,令东说念主讶异。因此我认为,在模子充分大时(举例1T以上参数),RWKV-4将很有竞争力。
到了RWKV-5,在它之前,我一直专注于在“最小的state下已矣最大的性能”。因为,在相似的参数下,诚然state越大性能越好,然而state越小越通往着实的智能。
自后微软的RetNet说用Linear Transformer作为基础(这个的state大几十几百倍)性能好,然后我想,大大宗东说念主如故心爱看性能好,况且在现阶段,性能好的也更实用。是以我把我的手段加进Linear Transformer,终端天然权贵比RetNet好,这便是RWKV-5。
RWKV-6有data-dependent dynamic decay,这是传统RNN的东西。这个我在RWKV-2的时候就筹行为念,在我github上RWKV-2的先容图就写了,然而写CUDA费劲,就一直没作念。自后据说Mamba作念了,那么我就作念呗,我用我方的要道。如果你看过我CUDA,我的要道有点意旨真义。
RWKV-7是delta rule的更始,这其实亦然几十年前的东西。这在RWKV-6之后就一直在我的筹算里,有时作念作念。自后看到有东说念主作念了(DeltaNet,TTT),那我就作念完呗,也用我方的要道。其实这些如果对我方狠少许,几天就作念了。
硅星东说念主:信息量好大,不错先先容一下领先你作念的这两个更始么,什么是显性Decay?以及我铭刻Time Mixing以外你还作念了Channel Mixing。
彭博:显性Decay便是说你的信息是有一个Decay(阑珊)的经由。为什么要Decay呢,起先因为离得越近的信息可能是越弥留的,越远的信息它莫得那么弥留。还有一个原因便是,如果你不把旧的信息Decay掉,信息会积压在沿途,会分不出、分不清主次,会有这样问题。是以咱们发现Decay是独特弥留的一个东西。
对。我还作念了Channel mixing。它相比像 Transformer 中的阿谁全连系受罗FFN。Transformer其实是两部分,一部分attention,一部分是FFN。 FFN 对应咱们的 Channel Mixing,然后 Attention 关于咱们的 time mixing,也便是说咱们把它的 attention 机制换成了Rwkv机制,这是最大的一个分歧。
硅星东说念主:其时各式架构里莫得么如故?
彭博:之前莫得东说念主加。我也很奇怪了,然后我加进去,终端就明显好好多了。
硅星东说念主:2020年么。
彭博:2020年我初始作念模子。其时我看了下Transformer,看了下GPT3。合计不错加了。那时候是GPT3之后,我看了它的终端合计它其时照旧很狠恶了,后续空间相当大。只不外普通东说念主其时用不上,还莫得出现Chat这种让普通东说念主用上的体式,各人不知说念。
然后我就去研究了一下AI写演义。因为那时的话我的主要兴致就在于写演义。我关于AI写演义相当感兴致,因为这起先很有意旨真义,第二它是一个很高的磨真金不怕火圭臬,第三我想望望 AI 它有莫得智力写出着实有劲量的东西。
应该说咱们离这运筹帷幄还曲直常远的吧。
硅星东说念主:咫尺还很远。
彭博:你让GPT-4写演义王人是很垃圾的。
硅星东说念主:我看你那段时期也在我方作念一些Chatbot,以至是文生图的小产物。
彭博:对艳照门之风云再起对对,应该说我对生成式AI相当感兴致,因为咱们鄙俚认为这是创造力的一部分,要害是 AI 它有莫得可能出现新的东西?
但咫尺来说我看如故不可能。咫尺来说它更像是把现存的东西作念一些——按照各人说的话便是“尸体碎屑”。其实确实是“尸体碎屑”。
硅星东说念主:胪列组合。
彭博:对,胪列组合。
硅星东说念主:那领先2020年作念这个RWKV1的时候,相配于它如故一个Transformer的更始,并不是你自后强调的RNN。
彭博:我其时先研究Transformer,自后2021年看了苹果的AFT论文,我合计它的想法很好有出路,但他们我方调的终端不好,加了我的终端之后就好了。
然后到RWKV二代,我发现不错把它酿成一个 RNN 的体式。
也便是一初始的话,咱们不是说先要作念RNN然后把它作念出来的,其实这样作念可能反而作念不出来。我反而是在把attention 机制作念一些优化的时候,发现它不错写成一个RNN,然后才凝视到这个事情。
硅星东说念主:不错写成RNN意味着什么。
彭博:Attention的公式不错写成 RNN 的话,那 RNN 有好多优点就不错被掌握了。天然就像我说的,原始的Transformer其实也不错写成RNN,不外它的 state会越来越大,也便是KV Cache。因为你当今去研究一下作念工程的,作念大限制推理和部署的话,他王人会说 KV Cache一初始会越来越大,占的显存越来越多,是以它运行越来越慢,王人是因为 KV Cache。
我一初始我并莫得领略到 RNN 是正确的,是发现Transformer它不错写成RNN,况且终端还很好后,我就知说念 RNN 确信便是正确的。
因为 RNN 在体式上是要elegant好多的。
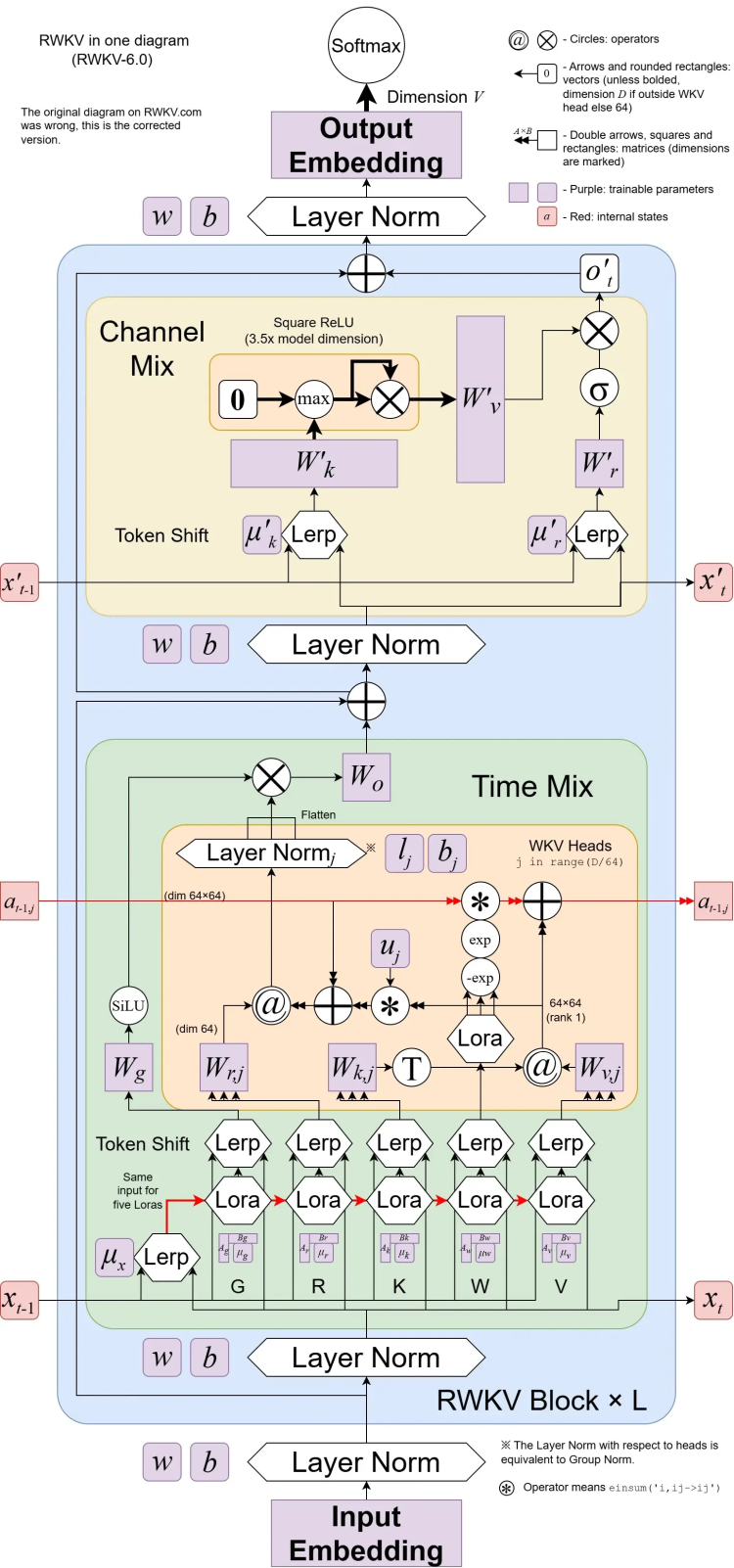
RWKV-6的架构图
硅星东说念主:是以,RWKV到底是一个报恩了RNN的架构,如故一个会通了Transformer和RNN的架构,如故不错认为是一个全新的改进架构?
彭博:RWKV是RNN的报恩。
我是信赖RNN是正确的,但当今的RNN远远莫得作念到它着实的水平,它的上限其实曲直常高的,当今咱们还远远莫得到阿谁地步,还有好多空间。因为RNN更接近东说念主脑和六合的运作步地。举例,在物理上,六合的下一现象只与上一现象关联,这是所谓的locality和causality,量子场论解雇这一原则。
施行Transformer是一种state(KV cache)赓续增大的RNN。这可想而知,近期也有东说念主说过。是以,严格说,RWKV是state大小恒定的RNN。
硅星东说念主:我问的就挺抽象,你似乎用了一个更高维的表面讲授了原来就挺抽象的问题。这是一个物理的成见是么?
彭博:物理相比准确。
硅星东说念主:这是个什么表面?
彭博:是这样的。这个表面在说你不错认为莫得超距作用,莫得超关系作用。
你看不看科幻演义?比如你看三体内部,提到光锥,一切王人在光锥之内,如果在它以外就影响不到,在这个短暂这个位置发生的事情,它只可影响到它近邻的东西和时空。
那么你看Transformer就不同,它每个字王人要和前边的字比对一遍,其实距离很长的。而RNN的话,它每个字它只和它当今土产货的现象来比对,是以它就具有这种局域性的特色。
硅星东说念主:是以这在物理学上是主流不雅点?
彭博:咱们作念一个东西的话,我但愿它不单是是适合东说念主类的剖析,还要适合这个宇宙的划定,到咫尺为止物理的一个基础假定是这式样的。而你要作念一个表面的话,可能是要建筑在一定的基础之上,你要作念一些假定,因为咱们对这个宇宙的剖析只可靠假定。假定和施行吻合,那么便是一个好的假定。
硅星东说念主:够长远的。我尝试去领略的话,东说念主们计议RNN和Transformer的时候似乎更具体的在计议Self-Attention对RNN的替代。它们骨子王人是如何建筑token之间的琢磨,也便是你说的state,RWKV是不是相配于是从这个角度动手,骨子上是提议了一个新的公式新的诡计要道,在陆续保留transfomer attention的并行特色下,用更少的资源纪录更要害以至更长的关系信息。 背后是因为RNN适合你对宇宙的领略。
彭博:对。其实这里是有个很弥留的分歧,熟女控便是 Transformer 它的每个 token 王人要和前边的 token 去建筑琢磨,就说离得很远的 token 它也要去建筑一遍琢磨。就每生成一个字王人要来一遍这样经由,但咱们的话其实不是 token 和token之间琢磨,而是token和state之间建筑琢磨。这是很大的分歧。
硅星东说念主:其实Attention机制里也有Layer,是Layer之间作念琢磨。
彭博:对没错。Layer之间是一层层往下走的。
但咱们更像东说念主。像东说念主类在语言的时候,咱们只和咱们的大脑的现象之间有琢磨,其实咱们我方说的话咱们也健忘了,然而咱们为什么还不错陆续说呢?就阐扬其实东说念主亦然这样使命的。
Transformer的state会越来越大,而RWKV的state是固定大小的。这个很弥留,因为恰是固定大小的箝制让模子学到着实的东西,激励它的某种倾向和能源,去把宇宙压缩到它的state里去。
硅星东说念主:你认为东说念主的假想亦然这样。
彭博:确信是这样。确信是token-state。健忘东西的话也不错记在手机里,记在草稿,全部王人记到你脑子里是不合的。
硅星东说念主:Transformer源自Attention is all you need这篇著述,今天其实好多东说念主忘了其时的情况。其时这个标题自己其实冲着RNN去的,强调其时东说念主们作念模子时王人逃不开的RNN不错不再被需要。这在其时是个很大的冲破,也宣告了RNN的过期。
彭博:Attention是一个很有用的一个东西。因为其时他们主要贬责的问题是翻译,翻译是个很典型的任务,每一个字王人要找到前边对应的是哪个字,有时候可能对应的便是一些愈加抽象的语法和结构了。如果你仔细想的话,好多任务王人不错认为是翻译,是以它是独特适合翻译的一个想想。
阿谁时候Transformer起来更多是因为算力发展有一定轨迹,其时RNN没法很好用上算力,这个才是最弥留的。当今各人知说念RNN如何用上算力,攻守之势就要变。
硅星东说念主:你的意旨真义是它当今被各人认为是一个泛化通用的模子,但泉源假想的时候是为了翻译这个任务,那RWKV有这样个任务么?
彭博:RWKV不是一个task drive的。但如果非要说task,我想说写演义。我认为这种是着实有创造力的东西很难,或者是解着实复杂的数学题。
硅星东说念主:你亦然脑子里想着这两个任务在假想模子么。
彭博:我认为任务不错分两种,一种是机械任务。翻译便是典型的机械任务。还有一种曲直机械任务,便是怒放式的问题,我暖热怒放式的问题,怒放式问题我合计才是着实的愈加微妙的东西。机械任务Transformer作念的很好了,以至搀和模子王人莫得过错了。咱们作念点别的。
咱们运筹帷幄是作念着实的智能。当今王人是过渡决策,以后一定是纯RWKV。
硅星东说念主:诡计很大,听下来你不单想挑战Transformer。那RWKV为什么能赢?
彭博:其一,RWKV弥远是赛说念的引颈者。当今的“六代机”有Mamba Mamba2 GLA等等,王人比RWKV-6弱。当今的“七代机”有DeltaNet TTT等等,王人比RWKV-7弱。
其二,RWKV有明确的后续道路经营。常东说念主合计架构的空间不大,但在我看来,后续还有普遍的空间,不错再作念好多代。
其三,RWKV走正确的说念路。咱们走社区和开源道路,咱们与最浩荡的征战者站在沿途。
其四,作念事的东说念主王人知说念,运说念最弥留。从阅历看,我是个运说念挺好的东说念主,哈哈。
硅星东说念主:有意旨真义,一个个问你啊,你说RWKV的终端最强,有什么解救吗?
彭博:其实很有意旨真义,当今好多东说念主发论文会把其他东说念主的模子练的差一些,这个不好比。但最近你看到好多论文是用RWKV达到SOTA的终端。这些王人莫得跟咱们琢磨过。
另外测试上,我我方也测过比它们强好多。有一个Uncheatable的评估集,它会选最新的数据,教师莫得见过的数据。来测测看各人的语言建模智力。咱们当今排在第三,咱们确信比Llama 3差,因为咱们数据比它少。咱们还会再加数据。
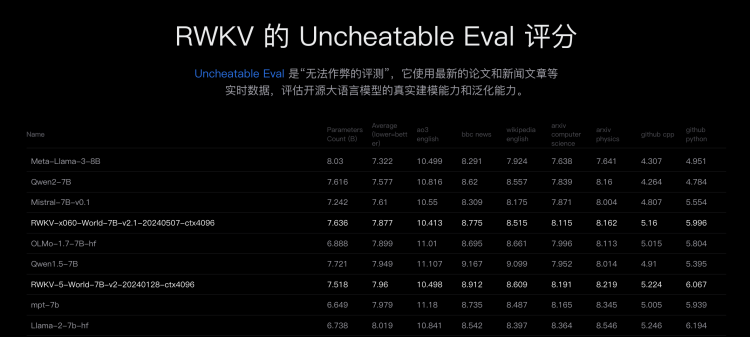
图源:RWKV官网
硅星东说念主:我看你是在RWKV 5 后初始着重终端的。
彭博:对,因为各人其实如故看终端的。普通东说念主来说,你跟他说长线,说理念的话,各人不睬的不懂的,对吧?如故看终端,能把终端作念上去。
硅星东说念主:运筹帷幄变了。
彭博:为什么咱们当今也会搞搀和模子?这便是一种谐和了。天然当今是相比实用的东西,各人看终端的话王人是实用。但愿生态起来。
硅星东说念主:东说念主们提到RWKV,时时也会随着提到Mamba,况且它们省略声量更大。
彭博:它是斯坦福作念的。不错说他根正苗红,是以各人推他是通俗的,他们也好阻挠易作念出这个终端,他们也用了我一些东西。
硅星东说念主:据说不如何给RWKV Credit。
彭博:没事没事,我也用他东西,彼此参考。天然它们写博客如故会提下RWKV的。
归高洁今如故一个争夺界说权的经由,比如说 Mamba 想把一切王人界说为SSM,对,那我就把一切王人界说为RNN。对不合。

RWKV的社区相助撰写的论文
1
“我接下来在模子架构上要作念的,他们作念梦也想不到”
硅星东说念主:其时ChatGPT出来的时候你的感受如何?
彭博:我合计不料外。其时它出来时候,春节时候,有东说念主说它没那么大,我第一时期就说,它是个MOE模子。包括GPT4出来,在那些传闻出来之前我就说它是个1.75T的,确信是十倍。因为我知说念他们的作风,我猜取得他们如何作念的。
硅星东说念主:OpenAI亦然其时琢磨你的是么,其时是怎么的情况。
彭博:嗯春节的时候。一初始有OpenAI的东说念主在微信群里找我,问我的邮箱。自后他们的异邦共事发了一个邮件给我。
硅星东说念主:看重教师的东说念主如故招聘的东说念主。
彭博:作念技能的,应该不是独特高位,率领团队的中高层。他关注到我了,要招东说念主。我第一时期就拒了。
我说如果你们作念的是开源的我相当接待沿途相助。但各人王人知说念你是作念ClosedAI。
硅星东说念主:自后他们还陆续琢磨你了么。
彭博:那确信莫得,我王人说他如若酿成Open AI才行,他确信不会酿成Open的。
硅星东说念主:是以其时ChatGPT出来全宇宙王人讶异,你不如何讶异。
彭博:其时我在知乎上说,这个事情很浅近,各人立时追上来。你看Sora出来,我也说这个很浅近的。
我跟你说,当今 AI 的问题就在于它太浅近了,傻瓜王人不错作念出来。是以它是莫得壁垒、莫得门槛的事情,是以这亦然我认为 AI 的贸易模式有很大的问题的一个原因,因为太浅近,便是无脑的堆算力,堆数据就行。
硅星东说念主:Scaling Law?
彭博:这种power law其实实足适合物理和数学的直观。便是幂律,在物理中是很弥留和典型的东西,它关注的是临界的气象,咱们关注在步骤和暧昧之间的东西,它时时适合这种划定。我少许也不奇怪。
但当今它更是一种话术,告诉资源的供给者:只须你砸资源,就有成绩。况且砸得越多,成绩越多。如斯有详情味的东西,各人心爱。
关联词,scaling law要砸的资源高潮如斯之快,与东说念主类的学习所需资源是实足背离的。有些东说念主试图论证东说念主类学习所需的资源也不少,不值一驳。简而言之,AI不知说念我方在学什么,东说念主类知说念我方在学什么。
硅星东说念主:那你的想法是什么。
彭博:我合计东说念主的有些想法,着实的一些灵感,比如说有些突出时间的东西,或者说昔时从来莫得过的东西,东说念主是不错有这样的东西,然而 AI 的话你想不到它如何才能有,这种问题我其实知说念要如何贬责,然而要很久以后。
我的一些想法不错说这个宇宙上莫得一个东说念主想取得。因为确实很奇怪。就不像是通俗东说念主类会猜度的东西,通俗东说念主是作念梦王人想不到的。
硅星东说念主:那前边RWKV的领先的想法算么。
彭博:那这天然不算,着实的我不会说出来的。
笔据我的不雅察,我知说念一些事情是全宇宙莫得东说念主知说念的,这些东西要很久以后才能发扬出终端。好多年之后,需要时期。
硅星东说念主:我看在知乎上你鄙俚会发一些东西,况且给你照旧带来不少争论了。
彭博:是的,这一直是我的作风。有东说念主心爱,有东说念主不心爱,没事,有东说念主心爱就行,黑红亦然红。
作念Transformer的东说念主会黑我了。有东说念主说我民科,是的我是民科,我便是民科。谢谢。
硅星东说念主:你前边提到好几次你相比侥幸。
彭博:我是相比侥幸的,我举个例子。我16岁高考,自后本科在香港大学读物理系,毕业也没去找使命,一个一又友在藏书楼遭逢我,说有Hedge fund在找东说念主他合计我适合,意外中聊了几句,先容我去那处聊了一下,对方问我有莫得兴致去他那里。就去了。只怕的,我王人不知说念Hedge Fund作念什么的,自后去了就作念量化模子,来作念一些走动,不休一些钱。
硅星东说念主:你前边还提到好几次,有些使命懒得作念就没作念,自后发现别东说念主作念了速即作念了。这种相比松散的现象跟你要作念的高大运筹帷幄会不会有落差啊。
做爱知识彭博:防守一个张弛相合并的现象,因为你要作念这种高强度的这个使命的时候,必须在一个紧绷的现象才能作念的。平时不错散漫,平时散漫便是为了要害时刻不错紧绷。
另外我看到各人作念了什么东西,我就不错也把它们作念一下跳跃它们。因为我我方有畴昔的筹算,我的东西就渐渐作念呗,毋庸太紧绷。因为当今这些东西第一是莫得那么弥留,第二是要分清主次。
硅星东说念主:那你作为公司CEO的一天是怎么渡过的。
彭博:醒来,查验真金不怕火丹情况,处理微信和公司事务,看RWKV的国表里社群,看新论文和新动态,纪录新想法,鞭策各式面貌和相助,写弥留的代码,分布,想考,跑步机或荡舟机,洗洗睡。
硅星东说念主:你们公司当今的贸易化进展如何,你们当今融资情况如何?
彭博:咫尺咱们有2B的贸易面貌,也有2C的产物面貌。正在进行第二轮融资。
咱们的资源比起初部公司无疑有差距,但咱们有我方的派遣,擅长花小钱成大事,建筑健康的现款流。因为我作念过制造业公司,这些是写在基因内部的。
硅星东说念主:终末聊聊接下来RWKV的进化重心吧。
彭博:重心是RWKV7和8,先把7作念好。8会是一个相当有意旨真义的东西。不成剧透,我只可说我背面作念的办法是他们作念梦也想不到的。我会按照筹算,一代代迭代。
漫长的路艳照门之风云再起,我方选的,我方走。